NVIDIA将采用X3D堆叠设计!下一代FeynmanGPU会引入LPU
2026-02-06 03:17:10kindsoft 来源:kindsoft
12月29日消息,尽管NVIDIA当前在AI训练领域占据着难以撼动的优势地位,但随着即时推理需求的不断攀升,该公司正酝酿一项可能颠覆行业现有格局的“杀手锏”技术。
据AGF方面消息,NVIDIA预计在2028年推出的Feynman(费曼)架构GPU产品中,将整合Groq公司研发的LPU(语言处理单元),旨在显著增强AI推理方面的性能表现。
Feynman架构将取代Rubin架构,采用台积电最先进的A16(1.6nm)制程工艺;为突破半导体物理层面的限制,NVIDIA拟借助台积电的SoIC混合键合技术,把专门针对推理加速设计的LPU单元直接堆叠于GPU之上。
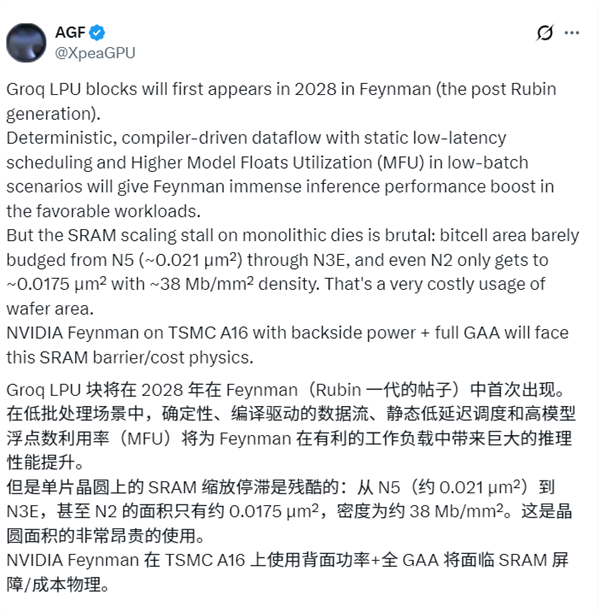
这种设计和AMD的3D V-Cache技术有相似之处,不过NVIDIA堆叠的并非普通缓存,而是专门针对推理加速打造的LPU单元。
设计的核心逻辑是SRAM的微缩难题,在1.6nm这样的极致工艺节点下,若直接在主芯片上集成大规模SRAM,不仅成本高昂,还会占据大量空间。
通过堆叠技术,NVIDIA可以将运算核心留在主芯片,而将需要大量面积的SRAM独立成另一层芯片堆叠上去。
台积电A16制程的一大亮点在于对背面供电技术的支持,该技术能够释放芯片正面的空间,专门用于垂直信号连接,从而保障堆叠的LPU在极低功耗下实现高速数据交换。
结合LPU所具备的“确定性”执行逻辑,未来的NVIDIA GPU在应对即时AI响应类任务(比如语音对话、实时翻译等场景)时,其处理速度有望达成质的飞跃。
不过这也面临两大潜在挑战,一是散热问题,二是CUDA兼容性难题。在运算密度本就极高的GPU上再叠加一层芯片,如何防止设备因过热而宕机,成为了工程团队需要优先解决的头号难题。
同时LPU注重“确定性”的执行顺序,对内存配置的精度有较高要求,而CUDA生态是依托硬件抽象化理念构建的,若想实现二者的无缝协作,离不开顶尖的软件优化技术支持。









相关资讯更多